

さて前回までは、学習をさせるためにタイタニック号の生存予測のためのデータの準備まで行いました。
今回は、準備したデータを作成したモデルに学習させ、Kaggleに提出してみましょう。
1.環境
言語:python
エディタ:spyder
フレームワーク:Tensorflow
2.作成フロー
□ライブラリのインポート
□決定木モデル作成
□学習
□予測
□提出
このような流れで作業していきたいと思います。
3.ソースコード詳細と説明
import pandas as pd import os import numpy as np from sklearn import tree
まず必要なライブラリをインポートしましょう。
今回は学習器に決定木を使用するため、scikit-learnで実装されている決定木分析をインポートします。
scikit-learnはpythonの機械学習ライブラリで、オープンソースなので誰でも無料で利用することができます。
scikit-learnは多くの機械学習アルゴリズムが実装されており、また多くのサンプルデータも備えているため、手元にデータがなくても、すぐに機械学習を始めることができます。
#作成csvデータのインポート
os.chdir('C:/Users/User名/ディレクトリ名/taitanic')
train = pd.read_csv('C:/Users/User名/ディレクトリ名/tai_train.csv')
test =pd.read_csv('C:/Users/User名/ディレクトリ名/tai_test.csv')
データの準備で作成したCSVファイルをインポートしましょう。
訓練データ:train
評価用データ:test
#目的変数と説明変数を決定して取得 target = train["Survived"].values explain = train[["Pclass","Sex","Age","Fare"]].values
訓練データから説明変数と目的変数を決定します。
説明変数:目的変数を説明する変数のこと。「独立変数」とも呼ばれ、物事の原因とも考えられる。
目的変数:予測したい変数のことで、「従属変数」「外的基準」とも呼ばれる。物事の結果とも考えられる。
今回の場合、目的変数は結果を示すものであるので「Survived」。
説明変数には、Pclass・Sex・Age・Fareの4つで見ていきます。
#決定木の作成 model = tree.DecisionTreeClassifier() #学習 model = model.fit(explain,target)
モデルの作成をしていきましょう。
決定木分析は、tree.DecisionTreeClassifier()というクラスを使用することでモデルを作成することができます。
学習はfit関数を使用するだけで完了です。fit関数は、
学習モデル = (作成したモデル). fit([説明変数],[目的変数])
という使い方をします。
#作成したモデルを用いて予測する test_explain = test[["Pclass","Sex","Age","Fare"]].values prediction = model.predict(test_explain)
次に、予測をしていきましょう。
まずtestデータから”Pclass”,”Sex”,”Age”,”Fare”の説明変数を抽出していきましょう。
predict()メソッドを使用し、説明変数を引数に指定し予測を実行。
#予測結果の出力 print(prediction.shape) print(prediction)
予測した結果を表示していきましょう。
以下のように、予測結果のサイズと結果の表示がされます。

#予測結果データとPAssengerIDを結合
PassengerID = np.array(test["PassengerId"]).astype(int)
result = pd.DataFrame(prediction,PassengerID, columns=["Survived"])
result.to_csv("Titanic_result.csv",index_label=["PassengerId"])
ここまで学習~予測までができました。
そしたら、いよいよkaggleに投稿です。投稿する前に、データを提出できる形に整えていきましょう。
要求されているデータフレームのカラムにはPassengerIdが必要なので、予測結果[“Survived”]と[“PassengerId”]を結合していきましょう。
結合の流れは、testから[“PassengerId”]をint型で抽出し、それをresultという変数名で、新規にデータフレームを作成します。
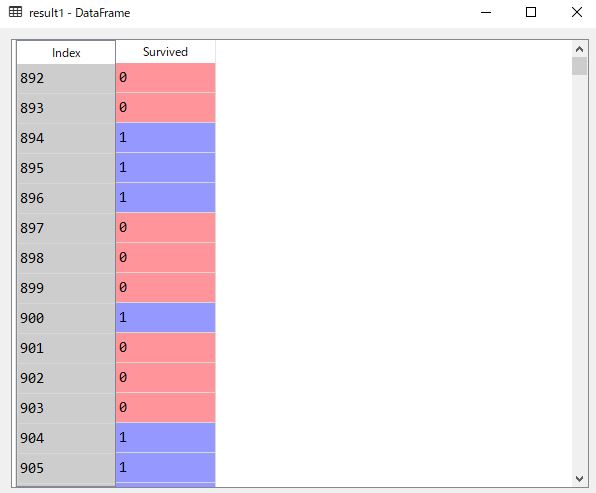
このまま保存すると、PassengerIdがindex名が”index”となってしまうので、indexを[“PassengerId”]に変更しcsvファイルとして保存しましょう。
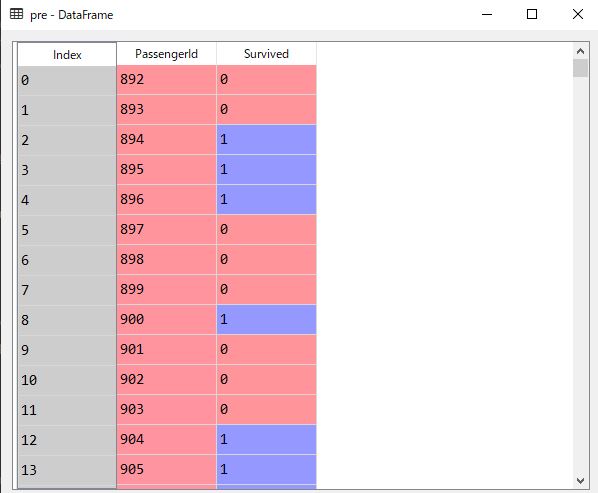
上の画像のようになればOKです。
4.ソースコード全文
import pandas as pd
import os
import numpy as np
from sklearn import tree
#作成csvデータのインポート
os.chdir('./taitanic')
train = pd.read_csv('./tai_train.csv')
test =pd.read_csv('./tai_test.csv')
#目的変数と説明変数を決定して取得
target = train["Survived"].values
explain = train[["Pclass","Sex","Age","Fare"]].values
#決定木の作成
model = tree.DecisionTreeClassifier()
#学習
model = model.fit(explain,target)
#作成したモデルを用いて予測する
test_explain = test[["Pclass","Sex","Age","Fare"]].values
prediction = model.predict(test_explain)
#予測結果の出力
print(prediction.shape)
print(prediction)
#予測結果データとPAssengerIDを結合
PassengerID = np.array(test["PassengerId"]).astype(int)
result = pd.DataFrame(prediction,PassengerID, columns=["Survived"])
result.to_csv("Titanic_result.csv",index_label=["PassengerId"])
5. Kaggleに予測結果を提出
ここからからタイタニックのコンペのページに行く。
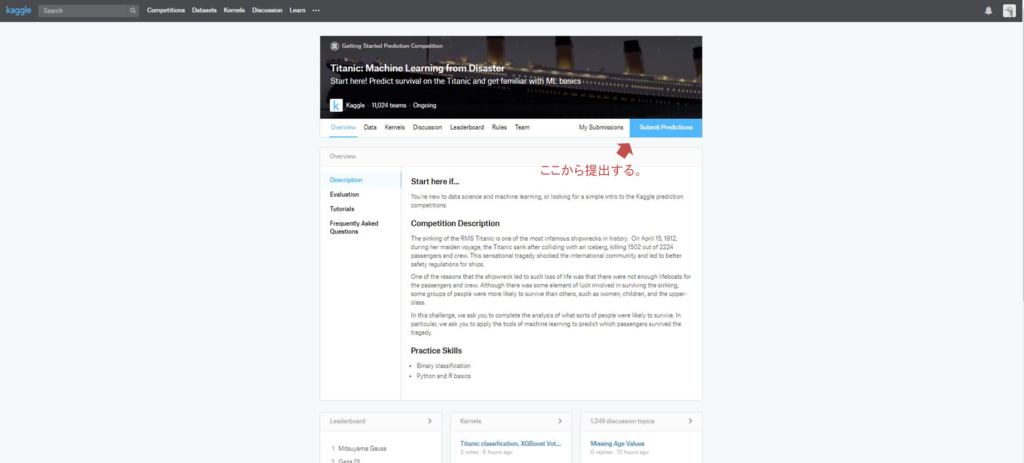
「Submit Prediction」から、作成したcsvファイルを提出ページに移動する。
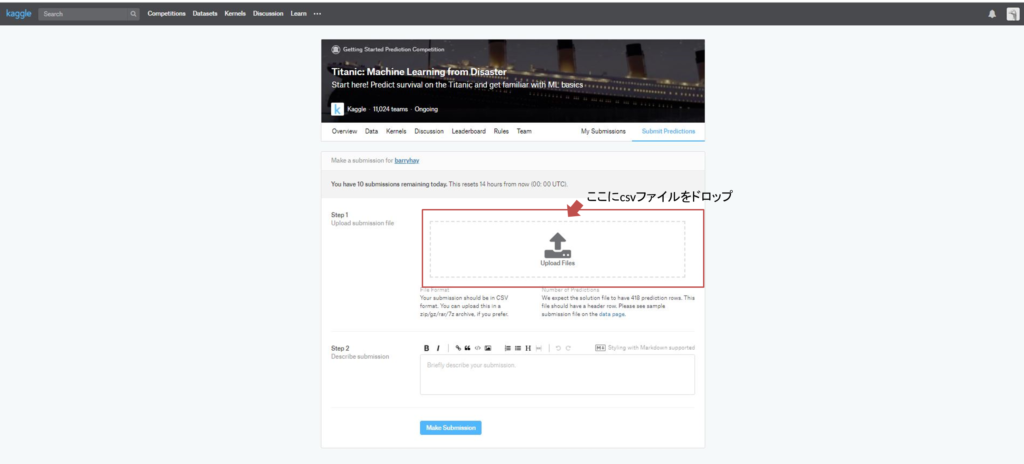
ファイルをアップしたら、「Make Submission」ボタンをクリック。
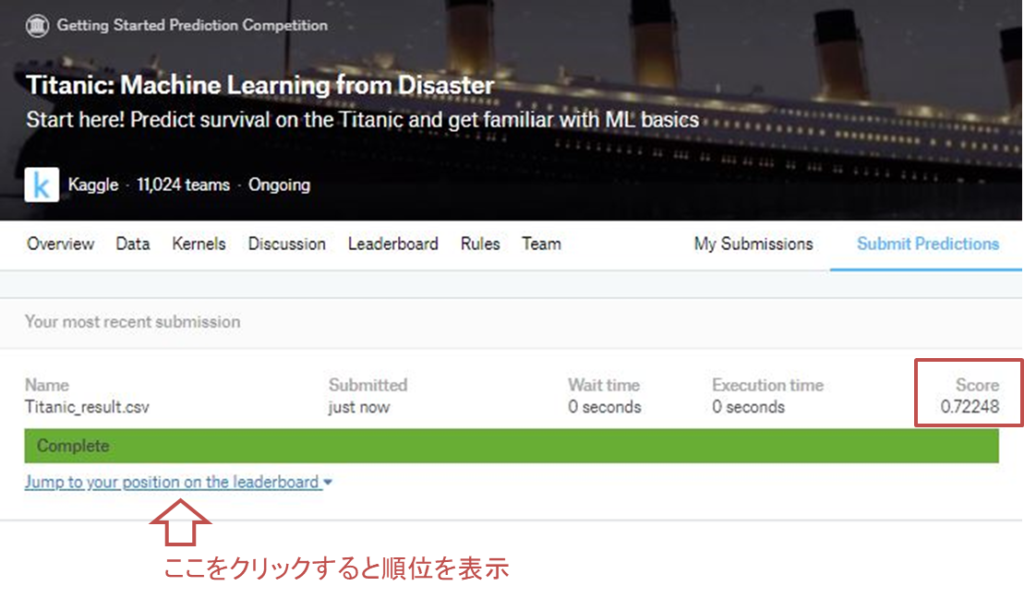
提出した結果は、Scoreというところに表示されます。今回は0.72248となりました。イマイチですね。
また「Jump to your position on the leaderboard」をクリックすると、自分の順位が表示されます。
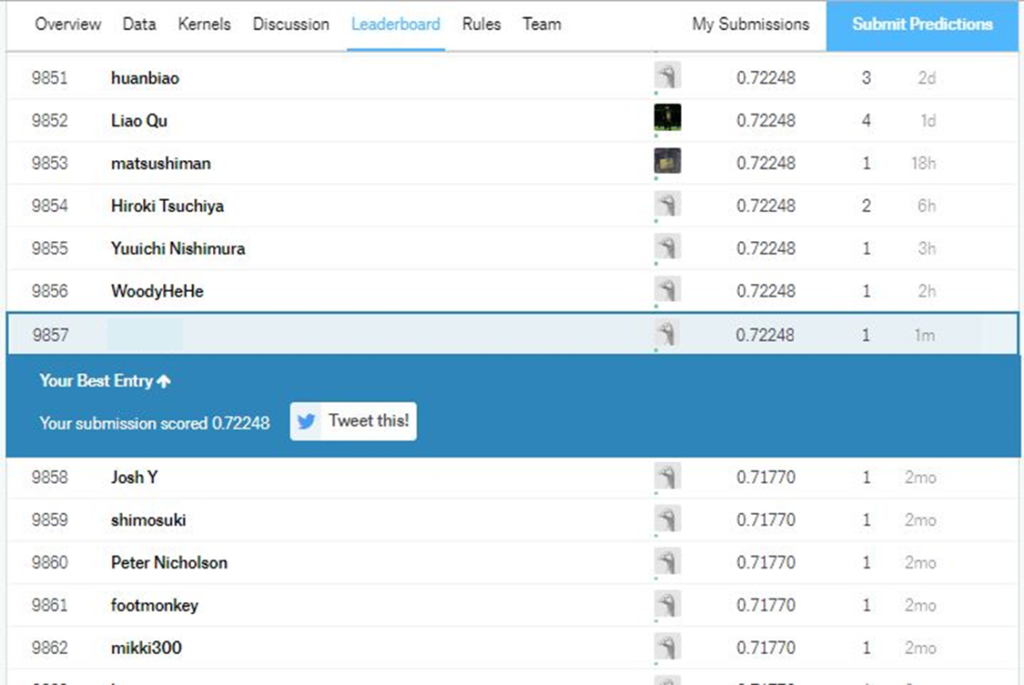
6.おわりに
今回は、モデルの作成から予測、さらにkaggleに提出までを行いました。
予測結果は72%ほどとイマイチな結果となりましたが、今後色々と試して精度を上げていきたいと思います。


コメント