

今回はkerasを使ってMNISTに挑戦したいと思います。
機械学習の有名な課題である、手書き文字認識のMNITSで機械学習プログラミングの練習をしていきたいと思います。
では、さっそくいってみましょう!
1.MNISTとは
MNIST(Mixed National Institute of Standards and Technology database)とは、「0から9までの70000枚の手書き画像で構成されたデータセット」で、画像分類の機械学習プログラムでよく使用されるデータセットの1つです。
MNISTは、用意された手書き文字のデータに、あらかじめ正解ラベルがついています。訓練用の画像が60000枚、テスト用の画像が10000枚用意されています。
この画像を解析し、正解ラベルを推定することが最終的な目的となります。
このMNISTを通して、学習はすでに完了したものとして、学習済みのパラメータを使用して、ニューラルネットワークの「推論」を実行したいと思います。
ちなみに、この推論処理はニューラルネットワークの順方向伝播(forward propagation)ともいいます。

(参照:http://dotnsf.blog.jp/archives/1070827338.html)
また、今回のMNISTや機械学習プログラムの流れなどの参考書は以下の2つです。
2.処理の流れ
・ライブラリのインポート
・MNIST_Dataのロード
・Dataを画像で確認
・特徴量の正規化
・モデルの構築
・学習の実行
・評価
3.ソースコードの流れ
# -*- coding: utf-8 -*-
#ライブラリのインポート
from keras.datasets import mnist
#dataのロード
(x_train, y_train), (x_test, y_test) = mnist.load_data()
#dataの確認
print("x_train: ",x_train.shape, " y_train: ",y_train)
print("x_test: ",x_test.shape, " y_test: ",y_test)
#dataを画像で確認
import numpy as np
from PIL import Image
def img_view(img):
pilIm = Image.fromarray(np.uint8(img))
pilIm.show()
img = x_train[4]
label = y_train[4]
print(img.shape)
img_view(img)
#特徴量の正規化
x_train = x_train.reshape((60000,28*28))
x_train = x_train.astype("float32")/255
x_test = x_test.reshape((10000,28*28))
x_test = x_test.astype("float32")/255
#モデルの構築
from keras.models import Sequential
from keras.layers import Dense, Activation
model = Sequential()
model.add(Dense(units=512, input_dim=784))
model.add(Activation("relu"))
model.add(Dense(10))
model.add(Activation("softmax"))
model.summary()
model.compile(loss="sparse_categorical_crossentropy",optimizer="sgd",metrics=["accuracy"])
#学習の実行
history = model.fit(x_train,y_train,epochs=100,verbose=1,validation_data=(x_test, y_test))
#dataの評価
test_loss, test_accuracy = model.evaluate(x_test, y_test)
print("****result******")
print("test_accuracy: ", test_accuracy)
4.ソースコード詳細
ライブラリとデータのインポート
#ライブラリのインポート
from keras.datasets import mnist
#dataのロード
(x_train, y_train), (x_test, y_test) = mnist.load_data()
#dataの確認
print("x_train: ",x_train.shape, " y_train: ",y_train)
print("x_test: ",x_test.shape, " y_test: ",y_test)
MNISTのデータはあらかじめkerasで用意されているモジュールを使用しました。
Point:mnist.load()モジュールの使い方
(x_train, y_train), (x_test, y_test) = mnist.load_data()
戻り値:x_train, x_test: shape (num_samples, 28, 28) の白黒画像データのuint8配列
戻り値:y_train, y_test: shape (num_samples,) のカテゴリラベル(0-9の整数)のuint8配列
dataのサイズを見てみましょう。(※初回のデータのロードは数分かかることがあります。)

手書き文字のサイズ:訓練データ60000枚、サイズ28*28、テストデータ10000枚、サイズ28*28
MNISTデータの画像化と確認
#dataを画像で確認
import numpy as np
from PIL import Image
def img_view(img):
pilIm = Image.fromarray(np.uint8(img))
pilIm.show()
img = x_train[4]
label = y_train[4]
print(img.shape)
img_view(img)
dataの画像化にはPILモジュールを使用します。
ここでは関数名img_viewとして画像化を定義します。
fromarrayメソッドは、配列の各値を整数型として画像のpixel値に変換することができます。
それでは、データの5番目を画像化してみましょう。
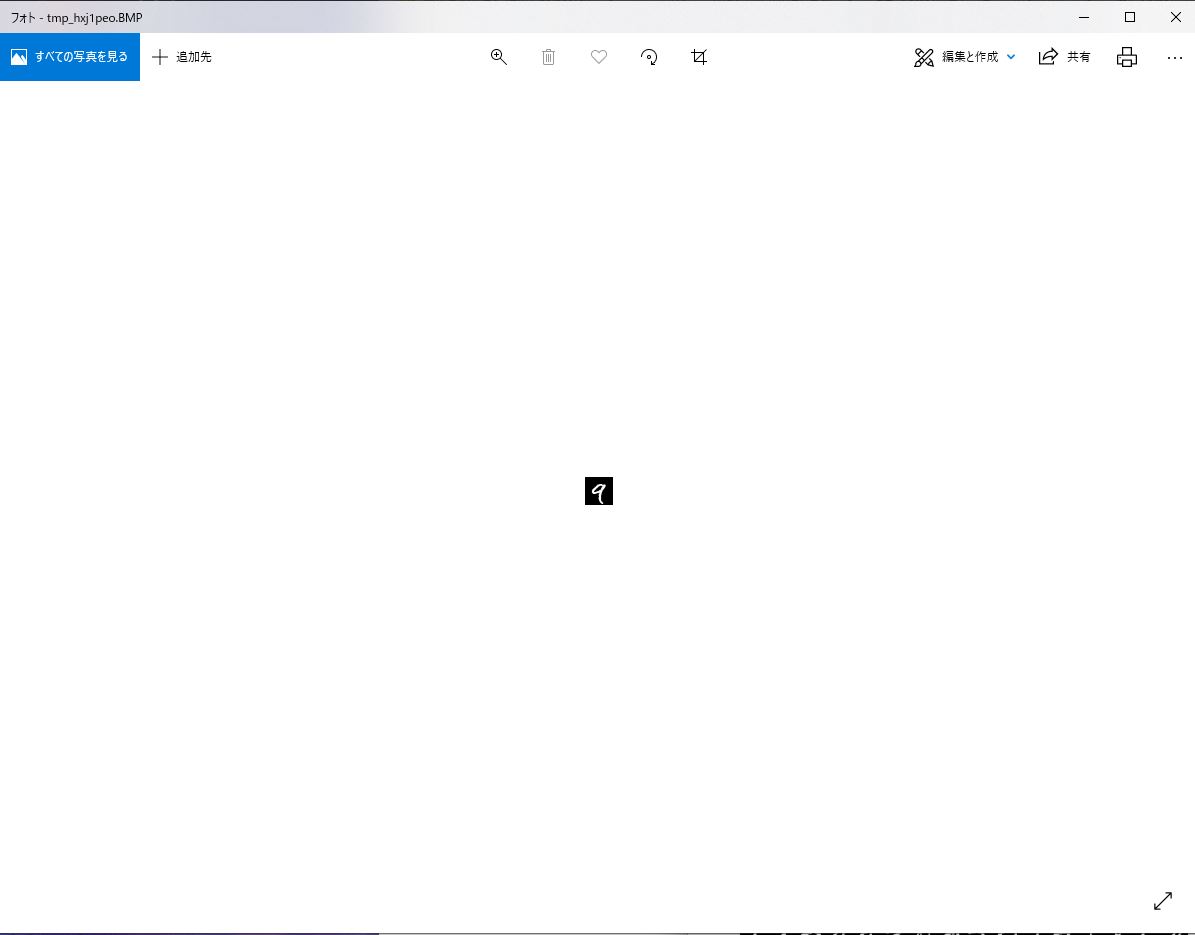
特徴量の正規化
次に特徴量の正規化をします。
#特徴量の正規化
x_train = x_train.reshape((60000,28*28))
x_train = x_train.astype("float32")/255
x_test = x_test.reshape((10000,28*28))
x_test = x_test.astype("float32")/255
ここでは、訓練用データとテストデータのどちらにも、255で除算しています。
データ内部の画像のピクセル値を255で除算すると、データの値を0.0~0.1の範囲に収まるように変換されます。
このようにデータを使用しやすく、かつある決まった範囲に変換することを正規化(normalization)といいます。
そして、このように何らかの決まった変換を行うことを前処理(pre-processing)といいます。
モデルの構築
model = Sequential()
model.add(Dense(units=512, input_dim=784))
model.add(Activation("relu"))
model.add(Dense(10))
model.add(Activation("softmax"))
model.summary()
model.compile(loss="sparse_categorical_crossentropy",optimizer="sgd",metrics=["accuracy"])
1行目:変数modelにSequential()モデルを格納
2行目:モデルに中間層を追加。中間層は512個のノードのレイヤで、入力層が28*28個のニューロン
3行目:活性化関数をモデルに追加。活性化関数はReLU関数を使用
4行目:出力層を10個とします。(0~9の10個のデータに分類するため)
5行目:活性化関数をモデルに追加。活性化関数softmax関数を使用
6行目:モデル概要を表示
7行目:モデルをコンパイルで構築(目的関数:sparse_categorical_crossentropy、最適化手法:SGD、評価関数:”accuracy”)
Point:目的関数と最適化手法とは
目的関数はニューラルネットワークから推定される値と正解ラベルの差を、どんな基準で差を決めるかという関数です。
そしてこの目的関数で決めた差を、どんな最適化手法で差を小さくするかを決定するのが最適化手法です。
model.summaryの実行結果は以下のようになります。

学習の実行
#学習の実行 history = model.fit(x_train,y_train,epochs=100,verbose=1,validation_data=(x_test, y_test))
学習にはhistoryという変数に、fit関数を使用して学習過程を格納します。
学習過程はこんな感じ。

学習の実行は、fit関数で実行します。
Point:fit()関数の使い方
model . fit( x, y, epoch, verbose, validation_data )
model : 作成した学習モデル
x : 訓練データ y : 正解データ
epoch:エポックとは単位を表します。1エポックは学習において訓練データを全て使い切った時の回数に対応します。
verbose:訓練状況を詳細に表示するかどうか。0.標準出力(画面)に表示されない。1.ログをプログレスバーで表示。2.エポックごとに1桁のログを出力
validation_data:各エポックの損失関数や評価関数で用いられるタプルデータを設定。訓練には使われない。
データの評価
#dataの評価
test_loss, test_accuracy = model.evaluate(x_test, y_test)
print("****result******")
print("test_accuracy: ", test_accuracy)
では、学習済みのモデルに評価用データを入力値として、結果を見てみましょう。
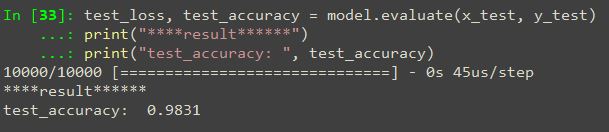 予測結果は0.9831とかなり高い結果となりましたが、過学習している可能性がありますね。
予測結果は0.9831とかなり高い結果となりましたが、過学習している可能性がありますね。
5.最後に
今回は、MNISTについて紹介をしました。
今度は、これをCNNを使って解析や、Chainerを使って挑戦してみたいと思います。


コメント