

今回は、機械学習プログラミングで用いられるデータの分割方法についてご紹介したいと思います。
この記事では、なぜデータ分割をする必要があるのかを説明した後、実際の分割方法としてscikit-learnが用意するtrain_test_split関数と、Chinerが用意するsplit_dataset_random関数についてご紹介したいと思います。
使い方だけ知りたい方は、3.と4.へ目次から移動してください!
1.データ分割をする理由
みなさん機械学習の問題に取り組むときは、訓練データとテストデータの2つに分けると思うのですが、なぜデータを分ける必要があるのか考えたことは一度はあると思います。
通常、機械学習はデータを入力し学習させて、訓練データだけを使って学習を行い、最適なパラメータを探索し更新していくのが、一般的な流れになると思います。
そしてその後、テストデータを使用して、訓練させたモデルを評価します。
では、なぜ訓練データとテストデータを分ける必要があるのでしょう。
理由は、汎化力を正しく評価するためです。機械学習のモデルを作るときに、そのモデルに求めることは汎化能力です。汎化能力とは、訓練データ以外に対して同じ性能を発揮できる能力を持つことです。
この汎化能力を獲得することが機械学習の最終的な目標です。
例えば、手書き文字の訓練データを全てモデルに学習させたとしましょう。
この学習モデルを使って、文字認識が非常に高い精度であったとしても成功とは言えません。理由は訓練データに含まれる「ある人の」クセ字や特徴だけを訓練しているのであって、このデータに特化したモデルができてしまっているからです。
そのため、ある特定のデータだけに過度に対応したモデルではなく、他のデータセットにも十分対応できるモデルを作成するために、訓練データとテストデータを分割させるのです。ちなみに、あるデータだけに過度に対応した状態の状態を過学習といいます。
では実際にデータ分割に挑戦していきましょう。
2.使用するデータの準備
今回使用するデータは、機械学習の入門で使用される、アヤメのデータセットを使用します。これはscikit-learnがあらかじめ用意したデータセットになります。
#datasetのインポート from sklearn import datasets #アヤメのデータを読み込み iris = datasets.load_iris() #特徴データ feature = iris.data #ラベルデータ target = iris.target
今回はデータに関する説明はしません。
詳細を知りたい方はこちらへ:kerasを使ってアヤメの分類
でもざっくり説明すると、
特徴データはがく片の長さ、がく片の幅、花びらの長さ、花びらの幅の4種類のデータが大量に格納されています。
ラベルデータは、ヒオウギアヤメ(setosa)・ブルーフラッグ(versicolor) ・Virginicaの3種類のアヤメ品種データが格納されています。
3.【scikit-learn】train_test_split関数
引数:test_sizeを指定する方法
#scikit-learnを用いたデータ分割 from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(feature, target, test_size=0.3)
まずimport文で、train_test_split関数をインポートしましょう。
次に、train_test_split関数の使い方についてです。
Point:train _test_split関数の使い方

変数は、訓練データ(特徴・ラベル)とテストデータ(特徴・ラベル)の計4種類を指定します。
引数のtest_sizeを指定する場合は、テストデータを何割に分割したいかを0~1.0の間で指定します。
この時、訓練データは指定しなくてもOKです。自動的に分割されるので。
引数:train_sizeを指定する方法
#訓練用データを指定するとき x_train, x_test, y_train, y_test = train_test_split(feature, target, train_size = 0.7)
今度は訓練データの分割割合を指定する場合です。これは、test_sizeの割合を決めたときと使い方は同じです。
Point: train _test_split関数の使い方

train_sizeは0~1.0の間で指定する。データ型はfloat型
評価データのサイズは指定しなくてもOKです。
引数:random_stateを指定する場合
ここでは、コードとその結果を記載します。
#ランダムシード(1回目)
>>>x_train, x_test, y_train, y_test = train_test_split(feature, target, test_size=0.3,random_state=1)
>>>print("訓練データ: ",x_train[0:5])
訓練データ: [[7.7 2.6 6.9 2.3]
[5.7 3.8 1.7 0.3]
[5. 3.6 1.4 0.2]
[4.8 3. 1.4 0.3]
[5.2 2.7 3.9 1.4]]
>>>print("検証用データ: ",y_train[0:5])
検証用データ: [2 0 0 0 1]
#ランダムシード(2回目)
x_train, x_test, y_train, y_test = train_test_split(feature, target, test_size=0.3,random_state=1)
print("訓練データ: ",x_train[0:5])
訓練データ: [[7.7 2.6 6.9 2.3]
[5.7 3.8 1.7 0.3]
[5. 3.6 1.4 0.2]
[4.8 3. 1.4 0.3]
[5.2 2.7 3.9 1.4]]
print("検証用データ: ",y_train[0:5])
検証用データ: [2 0 0 0 1]
ランダムシードは、シード値によってランダム値が決められており、シード値を同じ数字にすると毎回同じ疑似乱数が生成されるものです。
つまり、ランダムで分割する際に、再度分割する時も同じ条件で分割してほしいときに使用します。もちろんシードを指定しないと、分割後の値がランダムになります。
コードを見てみると、
ランダムシードを1を指定した1回目の訓練データ・検証データの結果と、2回目の訓練データ・検証データの結果を比較してみてください。
同一の数字の並びになっているのがわかります。
このようにシードによって分割後の値が固定されるのです。
Point:random_stateの指定の仕方

引数:shuffleを指定する場合
>>>x_train, x_test, y_train, y_test = train_test_split(feature, target, test_size=0.3,shuffle=True)
>>>print("訓練データ: ",x_train[0:5])
訓練データ: [[5.8 2.7 5.1 1.9]
[5.7 2.8 4.5 1.3]
[6.8 3.2 5.9 2.3]
[5. 3. 1.6 0.2]
[5.5 3.5 1.3 0.2]]
print("検証用データ: ",y_train[0:5])
検証用データ: [2 1 2 0 0]
引数にshuffleを指定する場合、datasetをシャッフルした上で分割されます。
Point:shuffleの指定の仕方
 シャッフルの指定は、shuffle=Trueもしくはshuffle=FalseでON/OFFできます。
シャッフルの指定は、shuffle=Trueもしくはshuffle=FalseでON/OFFできます。
次にChainerに用意されているデータ分割方法について紹介します。
3.【Chainer】split_dataset_random関数
Chainerでのdatasetの作り方
#Chainerを使ったデータ作成 >>>from chainer.datasets import TupleDataset >>>datasets = TupleDataset(feature, target) >>>datasets[0:10] Out[]: [(array([5.1, 3.5, 1.4, 0.2]), 0), (array([4.9, 3. , 1.4, 0.2]), 0), (array([4.7, 3.2, 1.3, 0.2]), 0), (array([4.6, 3.1, 1.5, 0.2]), 0), (array([5. , 3.6, 1.4, 0.2]), 0), (array([5.4, 3.9, 1.7, 0.4]), 0), (array([4.6, 3.4, 1.4, 0.3]), 0), (array([5. , 3.4, 1.5, 0.2]), 0), (array([4.4, 2.9, 1.4, 0.2]), 0), (array([4.9, 3.1, 1.5, 0.1]), 0)]
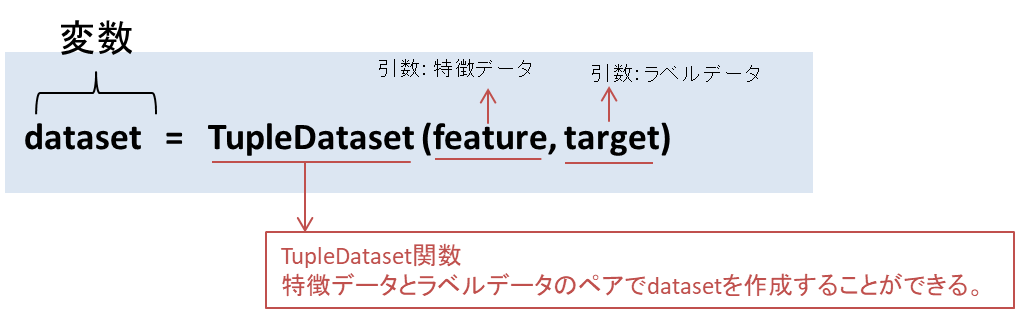
Chainerではデータセットの作成に便利なクラスがあります。
それは、TupleDataset関数です。 ndarrayをデータセットとして同様に扱えるように、入力値とラベルデータをセットでデータを作成することができます。
datasets[0:10]の出力結果を見てみると、
array([特徴データ], ラベルデータ)
という特徴データとラベルデータがペアでアクセスできるようになっています。
Point:TupleDatasetの使い方
Chainerを使ったデータ分割方法
>>>from chainer.datasets import split_dataset_random
>>>train_val, test = split_dataset_random(datasets, int(len(datasets)*0.7),seed=1)
>>>print("訓練データ: ", train_val[0:5])
訓練データ: [(array([5.8, 4. , 1.2, 0.2]), 0),
(array([5.1, 2.5, 3. , 1.1]), 1),
(array([6.6, 3. , 4.4, 1.4]), 1),
(array([5.4, 3.9, 1.3, 0.4]), 0),
(array([7.9, 3.8, 6.4, 2. ]), 2)]
ラベルデータ [(array([5. , 3.4, 1.6, 0.4]), 0),
(array([6.8, 2.8, 4.8, 1.4]), 1),
(array([5. , 3.5, 1.6, 0.6]), 0),
(array([4.8, 3.4, 1.9, 0.2]), 0),
(array([6.3, 3.4, 5.6, 2.4]), 2)]
Chainerにはデータ分割に関する関数も用意されています。
sklearnでされている関数とは違い、datasetはTupleDatasetで特徴データとラベルデータを1つにまとめてあるので、
あとはそのデータをどの割合で分割するか決めるだけです。
Point:split_dataset_random関数の使い方

4.まとめ
最後にデータセットの分割方法は様々です。scikit-learnやChainerが用意する関数を使用しなくても分割することができます。
しかし、各関数を使用することでコードも少なくなりエラーも起こりにくくなる可能性があります。
積極的に使用してみるといいかもしれませんね。


コメント
[…] 機械学習:訓練データとテストデータの分割方法 […]