

今回はscikit-learnで用意されているボストン市街の住宅価格(Boston house-prices)を回帰予測で調べてみたいと思います。
学習のモデルの種類は、回帰分析となります。
それでは実際にやってみましょう!
1.ソースコードの流れ
今回の作業の流れはこんな感じになります。
・ライブラリのインポート
・データのインポート
・データの可視化
・学習データとテストデータの分割と用意
・学習モデルの作成
・学習
・評価
2.ボストン市街の住宅価格のDatasetについて
次にデータセットの説明です。今回のデータは、scikit-learnが用意しているボストン市街の住宅価格(Boston house-prices)を使用します。
このデータを使って、最終的に導き出すものは、”ボストン市街の住宅価格の予測”です。
全データ:506件
属性データ:14件
| CRIM | 人口1人当たりの犯罪発生数 |
| ZN | 25000平方フィート以上の居住区間の占める割合 |
| INDUS | 小売業以外の商業が占める面積の割合 |
| CHAS | チャールズ川によるダミー変数(1:川の周辺,0:それ以外) |
| NOX | NOxの濃度 |
| RM | 住居の平均部屋数 |
| AGE | 1940年より前に建てられた物件の割合 |
| DIS | 5つのボストン市の雇用施設からの距離 |
| RAD | 環状高速道路へのアクセスのしやすさ |
| TAX | $10,000ドルあたりの不動産税率の総計 |
| PTRATIO | 町毎の児童と教師の比率 |
| B | 町毎の黒人(Bk)の比率を次式で表したもの。1000(Bk-0.63)^2 |
| LSTAT | 給与の低い職業に従事する人口の割合 |
| MEDV | 所有者が占有している家屋の$1000単位の中央値 |
参照サイト:Pythonでデータサイエンス
3.ソースコード
# -*- coding: utf-8 -*-
#ライブラリのインポート
from sklearn import datasets
import pandas as pd
import seaborn as sns
#ボストン市の住宅価格のデータのインポート
dataset = datasets.load_boston()
#データフレーム型に変換
df_data = pd.DataFrame(dataset.data,columns=dataset.feature_names)
df_data["PRICE"] = dataset.target
df_data.head()
#seabornのデータの可視化
sea_plot = sns.load_dataset("dataset")
sns.pairplot(df_data)
#ヒートマップで可視化
heat_map = df_data.corr(method="pearson")
sns.heatmap(heat_map,center=0,annot=True, cmap="Blues",fmt="1.1f")
#datasetの分割
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(dataset.data, dataset.target,test_size=0.3,random_state=0)
#学習
from sklearn import linear_model
model = linear_model.LinearRegression()
model.fit(x_train, y_train)
#予測精度の算出
print("train: ", model.score(x_train, y_train))
print("test: ", model.score(x_test, y_test))
#評価
test_df = pd.DataFrame(x_test, columns=dataset.feature_names)
print(test_df)
print(model.predict(x_test))
4.ソースコードの詳細
ライブラリのインポート
#ライブラリのインポート from sklearn import datasets import pandas as pd import seaborn as sns
まずはscikit-learnからデータのインポートをしましょう。
そしたら、インポートしたデータをDataFrame型に変換するためにPandasを、dataを可視化するためにseabornをインポートしましょう。
・sklearn : scikit-learnが用意するdatasets(データ群)のインポート
・pandas : DataFrame型にデータを変換する
・seaborn:データの可視化
Point:import文の使い方
import モジュール名
import モジュール名 as 別名
from モジュール名 import クラス名/関数名
データのインポート
#ボストン市の住宅価格のデータのインポート dataset = datasets.load_boston()
次に、scikit-learnからimportしたデータ群の中から、ボストン市の住宅価格だけを変数に定義します。
Point:datasetの定義
変数dataset = datasets.load_boston()
この一文の訳:「datasetsのload_boston()のデータを変数datasetに入れる」
ボストンのデータをDataFrame型に変換
#データフレーム型に変換 df_data = pd.DataFrame(dataset.data,columns=dataset.feature_names) df_data["PRICE"] = dataset.target df_data.head()
次にボストンの住宅価格のデータをpandasのデータフレームを使用して、データ型を変換していきます。
Point:pandasのデータフレームの使い方
変数 df_data = pd.DataFrame(data, index, columns, dtype, copy)
data : DataFrameに入れるデータを指定。辞書型・Numpy配列・DataFrameなど指定可。
index : 行のラベルを指定(今回は使用しない)
columns : 列のラベルを指定
dtype : データフレーム内のデータ型の指定
copy : bool型で指定し、オブジェクトを生成する際にコピーを生成するかどうか指定。
データの可視化
#seabornのデータの可視化
sea_plot = sns.load_dataset("dataset")
sns.pairplot(df_data)
まずはseabornのpairplotでデータを可視化してみましょう。
Point:seabornのpairplotでデータの可視化
sns.pairplot(data, hue)
data : DataFrame型でdataの指定
hue : カテゴリデータに従って色分け(今回はカテゴリが多いためエラーが発生)
これはさすがにわかりづらい・・・
では、次にヒートマップでデータを可視化していきましょう。
#ヒートマップで可視化 heat_map = df_data.corr(method="pearson") sns.heatmap(heat_map,center=0,annot=True, cmap="Blues",fmt="1.1f")
まずは使い方です。
Point:heatmapでデータを可視化
sns.heatmap(data, cmap, center, annot, fmt)
data : ndarray形式に変換可能な2次元のデータセットを指定。今回は相関係数を算出して適用。
cmap : matplotlibのカラーマップまたは、オブジェクトを指定。
center : colormapの中心とする値。
annot : Trueに設定するとセルに値を出力
fmt : データセットを指定した場合の出力フォーマットを文字列を出力
では出力されるヒートマップはこんな感じです。
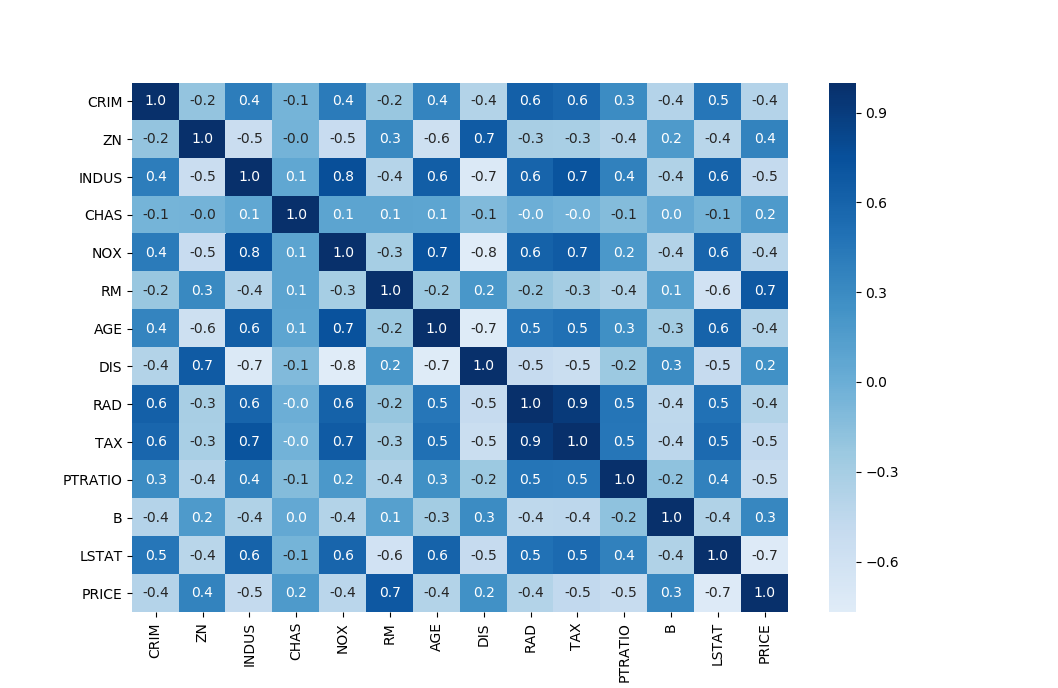
先程の散布図より圧倒的に見やすいですね。
このヒートマップから、最も相関が高いのがRMとPRICEですね。ここに何かしらの関係性がありそうですね。
訓練データとテストデータの分割
#datasetの分割 from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(dataset.data, dataset.target,test_size=0.3,random_state=0)
訓練データとテストデータの分割には、scikit-learnで準備されている train_test_split関数を使用します。
今回は、訓練データ:テストデータ = 7 : 3の割合で分割します。
<div “class=box5”>Point: train_test_split関数の使い方
x_train, x_test, y_train, y_test = train_test_split(data, target, test_size, random_state)
data : 分割したいデータ
target : 分割したいデータに対応したラベルデータ
test_size : テストデータのサイズの割合
random_state : ランダムシードを指定(今回は指定しない)
※データの分割の仕方の詳細はこちらをご覧ください。
学習モデルの作成
#学習 from sklearn import linear_model model = linear_model.LinearRegression()
まず今回は 線形回帰モデルを使用するので、sklearnからlinear_modelをインポートします。
LinearRegressionは線形回帰モデルの一つで、説明変数の値から目的変数をの値を予測するモデルです。
Point:学習モデルの定義
model = Linear_model.LinearRegression()
この式の説明「sklearnにあるLinear_modelのLinerRegression()関数を変数modelに定義」
学習の開始
model.fit(x_train, y_train)
学習はfit()関数を使用します。
Point:fit()関数の使い方
model . fit( x, y )
model : 作成した学習モデル
x : 訓練データ
y : 正解データ
予測精度の算出
#予測精度の算出
print("train: ", model.score(x_train, y_train))
print("test: ", model.score(x_test, y_test))
予測した精度はこんな感じにでました。
![]()
あんまり精度としてはよくないですね。
評価
#評価 test_df = pd.DataFrame(x_test, columns=dataset.feature_names) print(test_df) print(model.predict(x_test))
最後に評価です。
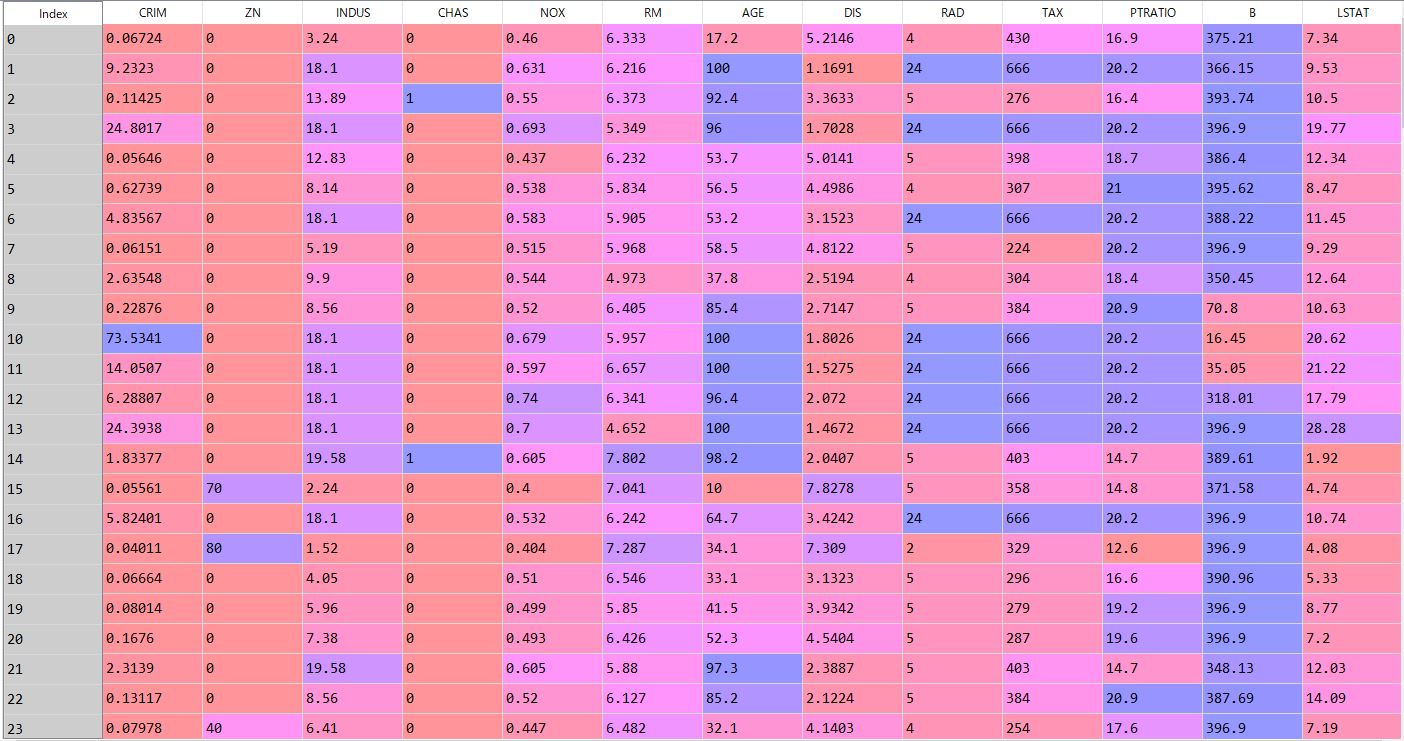
まずpandasのデータフレームを使ってテストデータを作成していきましょう。
indexの最初の部分はこんな感じです。(エディタ:spyder)
このデータは答えの情報になります。
そしてpredictアトリビュートで予測の仕方と予測結果をみていきましょう。
Point:model.predicrtの使い方
model.predict( data )
この一文の訳:modelのpredictを使ってdataの予測をする。
data : 予測したいデータ
では実際に予測した結果をみていきましょう。
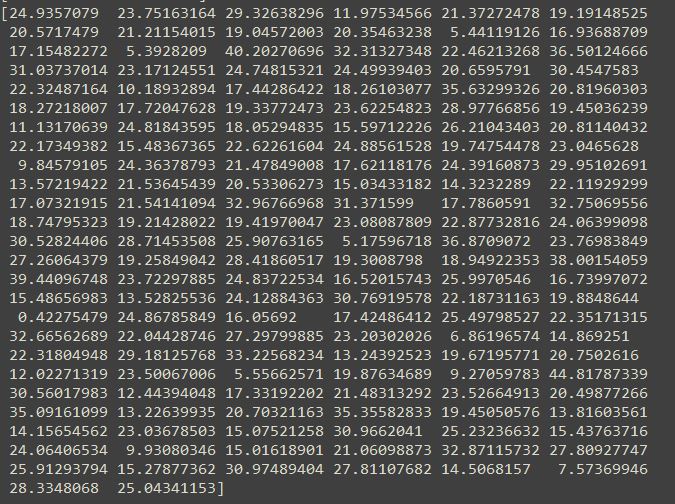 この数字の羅列は何かというと、ボストンの住宅価格予測結果です。
この数字の羅列は何かというと、ボストンの住宅価格予測結果です。
こんな感じで線形回帰を使って、scikit-learnのデータを予測しました。以上です。
6.最後に
今回は、scikit-learnのデータと線形回帰モデルを使って予測をしてみました。
他のデータを使って予測や回帰、さらには推論に挑戦していきたいと思います。

コメント