

今回はtensorflowとkerasを使用して、アヤメの分類を行います。
アヤメの分類は、機械学習の導入として用いられる教師あり学習サンプルです。
そしてkerasはPythonの深層学習ライブラリとして、とても有名です。
おそらく初心者の方で機械学習プログラミングを勉強する際に、ほとんどの方が挑戦するプログラムでしょう。
今回は、ライブラリのインポート、学習モデルの作成、学習器を使った予測を紹介したいと思います。
1.実装環境
言語:python
2.アヤメの分類
今回使用するアヤメのデータは、植物のアヤメを種類を決める上で必要な4つの属性があります。
1. がく片の長さ
2. がく片の幅
3.花びらの長さ
4.花びらの幅
上記の4つから、どの種類のアヤメに属するかを決定します。
ちなみに分類するアヤメは以下の3つになります。
・ヒオウギアヤメ(setosa)・ブルーフラッグ(versicolor) ・Virginica



3.プログラムコードの流れ
アヤメの分類を行う上で必要なプログラムコードの流れを説明します。
1. 必要なライブラリとデータのインポート
2. アヤメのデータをsklearnからインストール
3. アヤメのデータ150個を学習用120個、評価用に30個に分割する
4. 学習モデルの構築
5. 作成したモデルで学習
6. 学習モデルの評価
7. 評価と正答率の出力
4.ソースコード
今回使用したソースコードを記載します。詳細は次の章で説明します。
# -*- coding: utf-8 -*-
"""
Created on Tue Mar 26 22:11:02 2019
"""
#データのインポート
from sklearn import datasets
iris = datasets.load_iris()
#特徴ベクトル
iris_features = iris.data
#ラベルデータ
iris_targets = iris.target
#データの確認
print(iris.DESCR)
#学習に必要なパッケージをimport
from keras.models import Sequential
from keras.layers import Dense, Activation
from sklearn.model_selection import train_test_split
from keras.utils import to_categorical
import numpy as np
#機械学習に使用するデータを任意に分割
x_train, x_test, y_train, y_test = train_test_split(iris_features,iris_targets,train_size=0.8,test_size=0.2)
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
#機械学習で使用するモデルを作成
model = Sequential()
model.add(Dense(units=12, input_dim=4))
model.add(Activation('relu'))
model.add(Dense(units=3,input_dim=12))
model.add(Activation('softmax'))
model.compile(optimizer='SGD',loss='categorical_crossentropy',metrics=['accuracy'])
model.summary()
#学習の実行
model.fit(x_train, y_train, epochs=100, batch_size=25)
#学習モデルで予測 : 今回は適当なdataを予測に使用
pre_data = np.array([[5.1,3.5,1.4,0.2]])
r = model.predict(pre_data)
print(r)
print(r.argmax())
#学習器の評価
score = model.evaluate(x_test,y_test,batch_size=1)
print(score[1])
5.詳細なコードの説明
必要なdataのインポート
ここでは必要なdataをインポートします。
アヤメの属性データとラベルデータは、scikit-learnからデータを取得します。
scikit-learn(サイキット・ラーン)はPythonのオープンソース機械学習ライブラリで誰でも無料で使用できます。
scikit-learnは多くの機械学習アルゴリズムが実装います。またサンプルデータも豊富に用意されています。
今回はその中のアヤメのデータを使用します。
from sklearn import datasets iris = datasets.load_iris() #特徴ベクトル iris_features = iris.data #ラベルデータ iris_targets = iris.target
irisという変数には、scikit-learnからロードしたdatasetが格納されています。
特徴ベクトルには、アヤメの属性データ(高さ・長さ・幅など)の数値が入っています。
以下の画像は、実際にiris_featuresに格納されているデータです。
0列→がく片の長さ, 1列→がく片の幅, 2列→花びらの長さ, 3列→花びらの幅 と横にあり、
これが縦に150の配列あります。
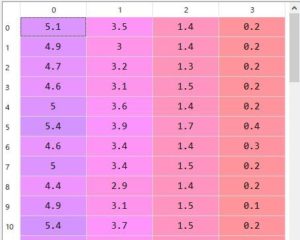
iris_featuresに格納されているデータ一覧
ラベルデータには、アヤメの品種が格納されています。各数値は以下の品種を表しています。
0 →[setosa] 1 →[Versicolour] 2 →[Virginica]
これも、iris_features同様に150配列のデータが用意されています。
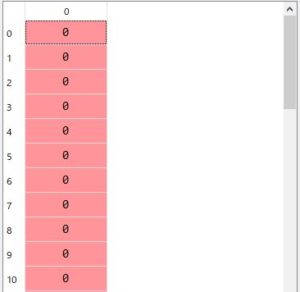
iris_targetsに格納されているデータの一覧
最後にデータ詳細を表示してみましょう。
#データの確認 print(iris.DESCR)
Iris plants dataset
--------------------
**Data Set Characteristics:**
:Number of Instances: 150 (50 in each of three classes)
:Number of Attributes: 4 numeric, predictive attributes and the class
:Attribute Information:
- sepal length in cm
- sepal width in cm
- petal length in cm
- petal width in cm
- class:
- Iris-Setosa
- Iris-Versicolour
- Iris-Virginica
:Summary Statistics:
============== ==== ==== ======= ===== ====================
Min Max Mean SD Class Correlation
============== ==== ==== ======= ===== ====================
sepal length: 4.3 7.9 5.84 0.83 0.7826
sepal width: 2.0 4.4 3.05 0.43 -0.4194
petal length: 1.0 6.9 3.76 1.76 0.9490 (high!)
petal width: 0.1 2.5 1.20 0.76 0.9565 (high!)
============== ==== ==== ======= ===== ====================
:Missing Attribute Values: None
:Class Distribution: 33.3% for each of 3 classes.
:Creator: R.A. Fisher
:Donor: Michael Marshall (MARSHALL%PLU@io.arc.nasa.gov)
:Date: July, 1988
ここには、アヤメのデータの詳細が記載されています。
ライブラリの準備
from keras.models import Sequential from keras.layers import Dense, Activation from sklearn.model_selection import train_test_split from keras.utils import to_categorical import numpy as np
まずkeras内のモジュールをインポートします。
kerasはPythonで書かれた、Tensorflow等で実行可能な高水準のニューラルネットワークライブラリです。
今回はkerasのライブラリの中から利用したいモジュールのみをインポートします。
Sequentialモデルは学習の層を重ねモデルを形成していきます。
ちなみに、学習器の作成のパターンは2種類あって、Sequentialモデルの他にfunctional APIがあります。これは追々説明していきます。
Sequentialモデルは.add()で層を追加していくことができます。
ここではざっとしか説明しませんが、import内容は以下の通りです。
Dense:中間層・隠れ層
Activation:活性化関数
train_test_split:データを任意の数に分割するためのモジュール
to_categorical:ラベルを0/1のラベルに変換するためのモジュール
numpy:これは数値計算を効率的に行うための拡張モジュール
学習データの加工・編集
#機械学習に使用するデータを任意に分割 x_train, x_test, y_train, y_test = train_test_split(iris_features,iris_targets,train_size=0.8,test_size=0.2) y_train = to_categorical(y_train) y_test = to_categorical(y_test)
ここでは、インポートしたデータを学習用/評価用に分割していきます。
train_test_splitを用いて、150個のアヤメのデータを学習用120個(0.8)、評価用30個(0.2)に分けます。
さらにラベルは、one-hot vectorにする必要があるため、to_categoricalを使ってラベルデータを0もしくは1のベクトルに変換する。
アヤメのラベルは、0 →[setosa] 1 →[Versicolour] 2 →[Virginica]に振り分けられています。
これをto_categoricalを使用すると、
print(y_train) [[0. 0. 1.] [0. 1. 0.] [0. 1. 0.] [0. 0. 1.] [1. 0. 0.] [1. 0. 0.] [1. 0. 0.]
print(y_test) [[0. 0. 1.] [0. 0. 1.] [1. 0. 0.] [0. 0. 1.] [0. 0. 1.] [0. 1. 0.] [1. 0. 0.] [0. 1. 0.]
このように、0と1のベクトルに変換されました。
ニューラルネットワークのモデル作成
#機械学習で使用するモデルを作成
model = Sequential()
model.add(Dense(units=12, input_dim=4))
model.add(Activation('relu'))
model.add(Dense(units=3,input_dim=12))
model.add(Activation('softmax'))
model.compile(optimizer='SGD',loss='categorical_crossentropy',metrics=['accuracy'])
model.summary()
line 1 : 線形スタックであるSeaquentialモデルの定義
line2 : 中間層をDenseで指定:中間層の数は12個,入力層は4個。
line3 : 中間層に適用する活性化関数はReLU関数を指定
line4 : 出力層をDenseで指定:3クラス分類のため出力は3、中間層は12次元のため入力次元は12
line5 : 出力層に適用する活性化関数はsoftmax関数を指定
line6 : kerasのcompile関数を使用して、最適化と損失関数の指定をします。
最適化:SGD 損失関数:categorical_crossentropy
line7 : summaryは、作成したモデルの要約を表示してくれます。
作成したモデルのイメージ図は以下の通り。
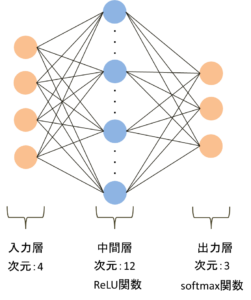
学習の実行
#学習の実行 model.fit(x_train, y_train, epochs=100, batch_size=25)
作成したモデルに、先ほど分割した学習用のデータを入力してモデルの学習をさせていきます。
学習には、fit関数を使用します。fit関数は指定したエポック数で学習を行います。
epochサイズは100、バッチサイズは25で学習させました。
ちなみに、バッチサイズは1回の学習の単位を決める数値、1回に学習に使用されるデータの束(まとまり)を表す数値となります。
エポックサイズは、バッチサイズによって分けられたデータで、何回学習を繰り返すかを表す数値になります。
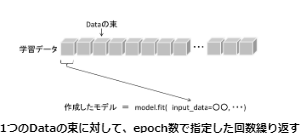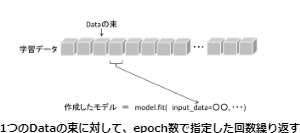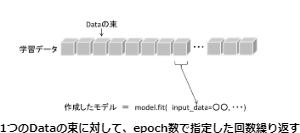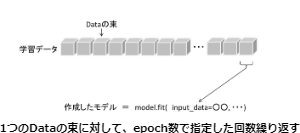
学習モデルを使用した予測
#学習モデルで予測 : 今回は適当なdataを予測に使用 pre_data = np.array([[5.1,3.5,1.4,0.2]]) r = model.predict(pre_data) print(r) print(r.argmax())
いよいよ、学習済みモデルを使用して、dataの予測です。
とりあえず、こちらで任意に決定したdataをpre_dataとして用意します。
このデータを学習済みのモデルに入れ、入力に対する予測をさせます。
argmax関数は配列で一番大きい要素のインデックスを返す関数なので、どのアヤメの番号に対応するかを確認します。
作成したモデルの評価
#学習器の評価 score = model.evaluate(x_test,y_test,batch_size=1) print(score[1])
最後に、データ分割で作成した評価データを使用し、モデルの評価を行います。
そもそも、このデータを学習用と評価用のデータに分割する理由は、簡易的に学習器の評価を行うためです。
機械学習はデータ量で精度が決まってしまうといっても過言ではないです。しかし現実問題、個人でそこまで学習用と評価用の大量のデータを収集できることは滅多にありません。
そのため、学習器の精度を評価するとなると 、現状手持ちのデータをうまく使用して学習と評価をさせる必要があります。
そこで、用意したデータを学習用と評価用の2つに分割したのです。ただ、実際はデータの量だけで精度を評価するというわけではなく、様々な方法を使用してモデルの評価をしていきます。
おわり
いかがだったでしょう。Python + kerasを使用することで簡単にAIプログラミングを実装することができます。
この機会に、皆さんも人工知能をかじってみてはどうですか。
コメント
[…] 詳細を知りたい方はこちらへ:kerasを使ってアヤメの分類 […]