

皆さん、こんにちは! ぶたキムチです。
今回はChainerを使ってアヤメの分類に挑戦していきたいと思います。
先日、Preferred Networks(PFN)が、Chainerを使ったディープラーニング入門を無料で公開しました。それを前回使ってみて、Chainerを使って機械学習プログラミングに挑戦したいと思ったので、今回はアヤメの分類問題に挑戦した結果をまとめました。
1.開発環境
macOS Mojave ver10.14.1
言語:python
フレームワーク:Chainer
使用したエディタ:Spyder
2. コードの流れ
コードの流れは、Chainerニューラルネットワーク入門を参考にしました。
Step1. 必要なライブラリのインストール
Step2. データセットを決める
Step3. ネットワークを決める
Step4. 目的関数・最適化手法を設定する
Step5. ネットワークの訓練
Step6. ネットワークを訓練結果の出力
3.ソースコード
# -*- coding: utf-8 -*-
#アヤメの分類問題
#skleranからirisのデータ準備
from sklearn import datasets
import seaborn as sns
import numpy as np
#学習に必要なパッケージを取得
import chainer
import chainer.links as L
import chainer.functions as F
from chainer.training import extensions
from chainer.datasets import TupleDataset
#irisデータセットの読み込み
iris = datasets.load_iris()
#特徴ベクトル
iris_features = iris.data
#ラベルデータ
iris_targets = iris.target
#データの確認
print(iris.DESCR)
#データの可視化
iris_plot = sns.load_dataset("iris")
sns.pairplot(iris_plot,hue="species")
#データ型の変換
iris_features = iris_features.astype(np.float32)
iris_targets = iris.target.astype(np.int32)
print("iris_features:",iris_features.dtype, " iris_targets:",iris_targets.dtype)
#学習データの分割
datasets = TupleDataset(iris_features, iris_targets)
from chainer.datasets import split_dataset_random
train_val, test = split_dataset_random(datasets, int(len(datasets)*0.7),seed=1)
#学習モデル作成
class IrisChain(chainer.Chain):
def __init__(self,):
super(IrisChain,self).__init__(
fc1 = L.Linear(4,5),
fc2 = L.Linear(5,5),
fc3 = L.Linear(5,3),
)
def __call__(self,x):
h1 = F.relu(self.fc1(x))
h2 = F.relu(self.fc2(h1))
out = self.fc3(h2)
return out
epoch = 50
batch_size=4
#optimizerのセット
model = L.Classifier(IrisChain())
optimizer = chainer.optimizers.SGD()
optimizer.setup(model)
train_iter = chainer.iterators.SerialIterator(train_val, batch_size, repeat=True, shuffle=True)
updater = chainer.training.StandardUpdater(train_iter,optimizer,device=-1)
trainer = chainer.training.Trainer(updater, (epoch, "epoch"), out = "result/iris")
test_iter = chainer.iterators.SerialIterator(test, 1,repeat=False, shuffle=False)
trainer.extend(extensions.Evaluator(test_iter, model, device=-1))
trainer.extend(extensions.LogReport())
trainer.extend(extensions.PrintReport( ['epoch', 'main/loss', 'validation/main/loss', 'main/accuracy', 'validation/main/accuracy']))
trainer.extend(extensions.ProgressBar())
#学習の実行
trainer.run()
#結果のグラフ化
import json
import pandas as pd
f = open("result/iris/log")
json_data = json.load(f)
df_result = pd.DataFrame(json_data)
df_result.tail()
df_result[["main/accuracy","validation/main/accuracy"]].plot()
df_result[["main/accuracy","validation/main/loss"]].plot()
3.ソースコード詳細
Step1.必要なライブラリをインポートする
#skleranからirisのデータ準備 from sklearn import datasets import seaborn as sns import numpy as np #学習に必要なパッケージを取得 import chainer import chainer.links as L import chainer.functions as F from chainer.training import extensions from chainer.datasets import TupleDataset
今回はscikit-learnが準備しているアヤメのデータをインストールしていきます。
アヤメの分類は機械学習の初心者練習問題として使用されるデータです。
そのデータを使ってChainerを使用していきます。
Point : import文の使い方
import モジュール名
from モジュール名 import クラス名/関数名など
import モジュール名 as 別名
Step2. データセットを決める
アヤメの特徴データとラベルデータの定義
#irisデータセットの読み込み iris = datasets.load_iris() #特徴ベクトル iris_features = iris.data #ラベルデータ iris_targets = iris.target #データの確認 print(iris.DESCR)
ここでscikit-learnのdatasetsからアヤメのデータを抜き出し、その中から特徴ベクトルとラベルデータを変数に入れましょう。
print(iris.DESCR)で得られるデータは以下感じです。

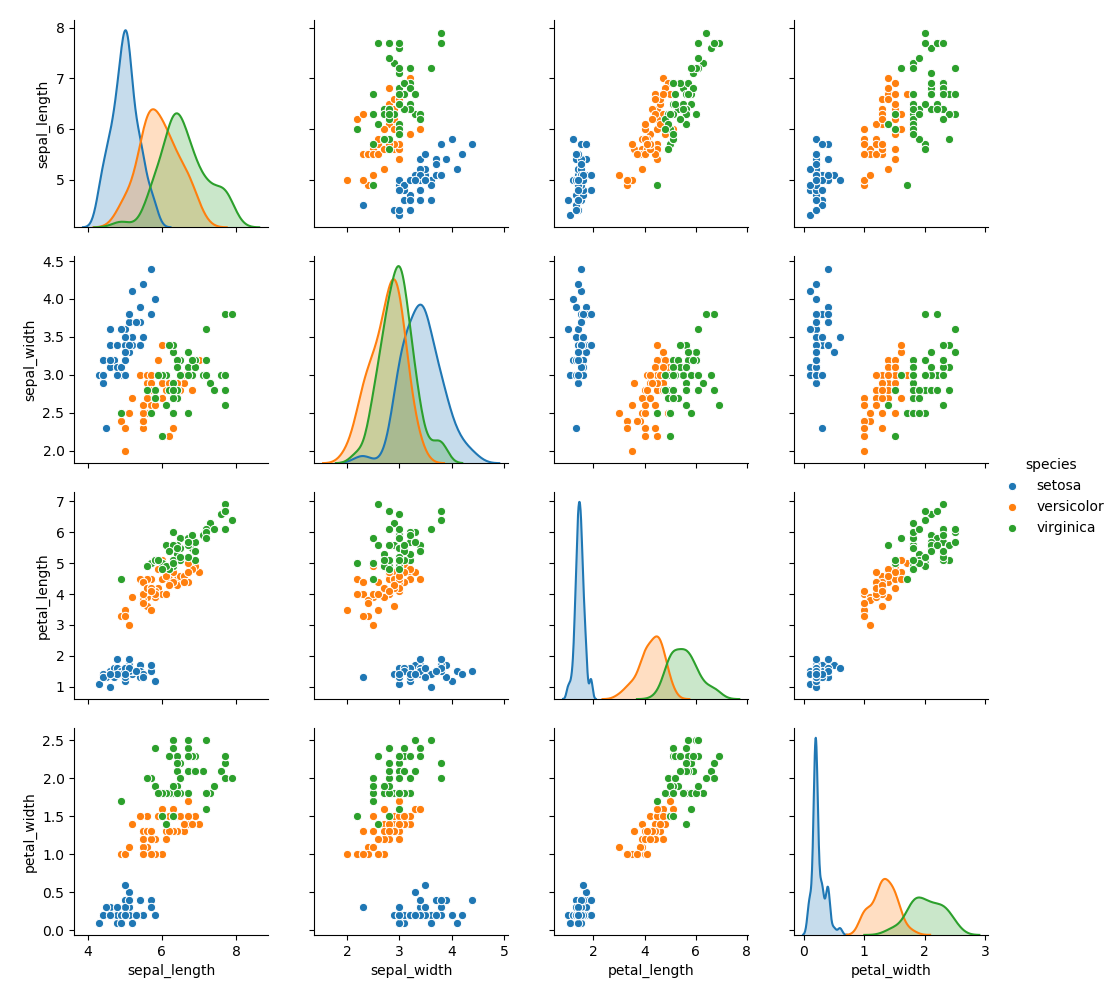
アヤメのデータの可視化する
#データの可視化
iris_plot = sns.load_dataset("iris")
sns.pairplot(iris_plot,hue="species")
Point:seabornのpairplot(散布図)の使い方
seaborn.pariplot( data, hue )
data : グラフ化したいデータ。データの型はDateFrame型
hue : カテゴリカルデータにならって色分け。指定できるのは列データにあるindex名
結果
【重要】アヤメのデータ(特徴・ラベル)の変換
#データ型の変換
iris_features = iris_features.astype(np.float32)
iris_targets = iris.target.astype(np.int32)
print("iris_features:",iris_features.dtype, " iris_targets:",iris_targets.dtype)
Chianerでは入力するデータの型を指定する必要があります。アヤメの特徴データはnumpy.float32にしなければなりません。そしてアヤメのラベルデータはnumpy.int32に変換する必要があります。numpy配列であるndarrayはastypeで変換可能することができます。
Point :astype()関数の使い方
data1. astype(np.変換したデータ型)
data1:変換したいデータ
変換したデータ型:int型やfloat型など
アヤメのデータを訓練データと検証データに分割する
#学習データの分割 datasets = TupleDataset(iris_features, iris_targets) from chainer.datasets import split_dataset_random train_val, test = split_dataset_random(datasets, int(len(datasets)*0.7),seed=1)
Chainerには便利なクラスがいくつかあります。それがTupleDatasetです。これは何かというと、アヤメのデータで分けた特徴データとラベルデータを1つずつペアで配列を作成し返してくれるものです。
Point:TupleDatasetsの使い方
datasets = TupleDataset(features, targets)
datasets:変数
features:特徴データ
targets:featuresに対応するラベルデータ
データの分割にはsplit_dataset_random()関数を使用します。
Point:split_dataset_randomの使い方
data, test = split_dataset_random(datasets, int(len(datasets)*0.7),seed=1)
data : 訓練用データ test:検証用データ
int(入力するデータ) : データ型を指定し変換
*0.7 : ここの数字は訓練データ何割にするか指定する数字。0.1~0.9で指定すると、全体から訓練データを指定した割合で分割。
seed:0 or 1を指定。1の場合、データセットを分割するデータをランダムにはせず、何回分割しても分割されたデータの中身はいつも同じになる。0の場合はデータの中身は分割するごとにランダム。
Step.3 ネットワークを決める
学習モデルを作成
今回作成したモデルは、全結合層3層のモデルを作成します。入力層はアヤメの特徴データの4、中間層は5、出力層には3種類のアヤメに分類するので3にパラメータを設定しました。
#学習モデル作成
class IrisChain(chainer.Chain):
def __init__(self,):
super(IrisChain,self).__init__(
fc1 = L.Linear(4,5),
fc2 = L.Linear(5,5),
fc3 = L.Linear(5,3),
)
def __call__(self,x):
h1 = F.relu(self.fc1(x))
h2 = F.relu(self.fc2(h1))
out = self.fc3(h2)
return out
ここではリンクを複数まとめたChainクラスを作成します。Chainクラスはリンクを継承しており、リンクを保持しておくことができるため、リンクと同様に扱うことができます。複数のリンクやファンクションを組み合わせた独自の層を作るのに使うことや、ネットワークの部分構造を記述や、それ自体で1つのネットワークの定義をすることができます。(参照:Cahiner Tutorialより)
Chainerではニューラルネットワークの層を構成するための微分可能な関数が用意されています。関数は以下の2つが挙げられます。
1.パラメータを持つ関数(層):リンク → 入力層・中間層・出力層・全結合層など
===> モジュール:chainer.links
2. パラメータを持たない関数:ファンクション → シグモイド関数やReLU関数といった関数など
===> モジュール:chainer.functions
モデルを作成する時、def __init__(self,) と def __call__(self,x):のイメージですが、
def __init__(self,):ニューラルネットワークの__init__に必要な層をどんどん積み上げていく感じ。
def __call__(self,x):伝播。こちらは各層にどんな関数を適用していくか、層自体に機能を追加していく感じ。
今回は、層結合層のL.Linear、活性化関数にはRelu関数を使用しました。
Point:Chainerでニューラルネットワークモデルの作成の仕方
class モデル名(chainer.Chain):
def __init__(self,):
super(モデル名,self).__init__(
変数1 = L.Linear(○,○),
変数2 = L.Linear(○,○),
)
def __call__(self,x):
変数3 = F.relu(self.変数1(x),
out = self.変数4(h2)
return out
クラスと継承については以前まとめたので、よかったら是非。
Step4. 目的関数と最適化手法を決める
optimaizerの設定
#optimizerのセット model = L.Classifier(IrisChain()) optimizer = chainer.optimizers.SGD() optimizer.setup(model)
まず学習をする前に、予測した値と実際の値の誤差を計算する必要があります。今回は分類問題を取り扱うので、Classifierを使うと便利。
次に、optimizerです。これは逆伝播するときに重みのパラメータを、更新し最適化するフェーズになります。
今回は、確率的勾配降下法(Stochastic Gradient Descent:SGD)を使用しました。
確率的勾配降下法は学習データをシャッフルした上で学習データの中からランダムに1つ取り出して誤差を計算し、パラメータを更新します。増加分の学習データのみで再学習するため計算量が少ない利点がある。
(参考サイト:http://yaju3d.hatenablog.jp/entry/2017/08/27/233459)
Point:optimizerの使い方
optimizer = cahiner.optimizers.最適化関数()
optimizer . setup(モデル名)
最適化関数():AdamやSGDが有名です。
setup関数は()内の入力値にモデル名を入れると適用される。
Iteratorの設定
train_iter = chainer.iterators.SerialIterator(train_val, batch_size, repeat=True, shuffle=True) test_iter = chainer.iterators.SerialIterator(test, 1,repeat=False, shuffle=False)
これもChainerの便利機能で、訓練データを毎エポックで順序をシャッフルしてくれるイテレーター(Iterators)を使用します。Chianerではネットワークの訓練データの順番をシャッフルすることでデータセットへの操作を抽象化してくれます。
Point:イテレータ(iterators)の使い方
iter = chainer.iterators.SerialIterator(data, batch_size, repeat=True, shuffle=True)
data:訓練データ(もしくは検証用データ)
batch_size:バッチサイズ。いくつのサブセットに分けるかを指定。
repeat=bool型:Trueの場合は無限に繰り返す。Falseの場合、1エポック分を返すと処理が終了する。基本True。
shuffle=bool型:Trueの場合はランダムな順序でデータを返す。Falseの場合はデータセットと同じ順序で返す。
Step.5 ネットワークの訓練
学習を始める準備:Updater
updater = chainer.training.StandardUpdater(train_iter,optimizer,device=-1)
updaterは何かというと、実際にoptimizerを更新する関数になります。
Point:updaterの使い方
updater = chainer.training.StandardUpdater(iter, optimizer, device=-1)
iter:イテレータでシャッフルされた訓練データ
optimizer:データに適用したい最適化手法
device:実装にGPU(=0)かCPU(=-1)どちらをしようするかを指定。
学習を始める準備:Trainer
#trainerの準備 trainer = chainer.training.Trainer(updater, (epoch, "epoch"), out = "result/iris") #extendの設定 trainer.extend(extensions.Evaluator(test_iter, model, device=-1)) trainer.extend(extensions.LogReport()) trainer.extend(extensions.PrintReport( ['epoch', 'main/loss', 'validation/main/loss', 'main/accuracy', 'validation/main/accuracy'])) trainer.extend(extensions.ProgressBar())
次にTrainerです。Trainerは学習を実行するのに必要なコードになってきます。学習ループを制御したり、Extentionを使用することでログの保存や、学習経過の可視化を行うことができます。
Point:Trainerの使い方とExtentionの設定
trainer = chainer.training.Trainer(updater, (epoch, “epoch”), out = “ログの保存先”)
updater:trainerを使う場合はupdaterを渡す必要がある。
(epoch, “epoch”):エポック数を指定する。”epoch”の部分は自分がエポックとわかれば、なんでもいい。
out:学習ログの保存先を指定する(ディレクトリの指定)
ネットワークの訓練
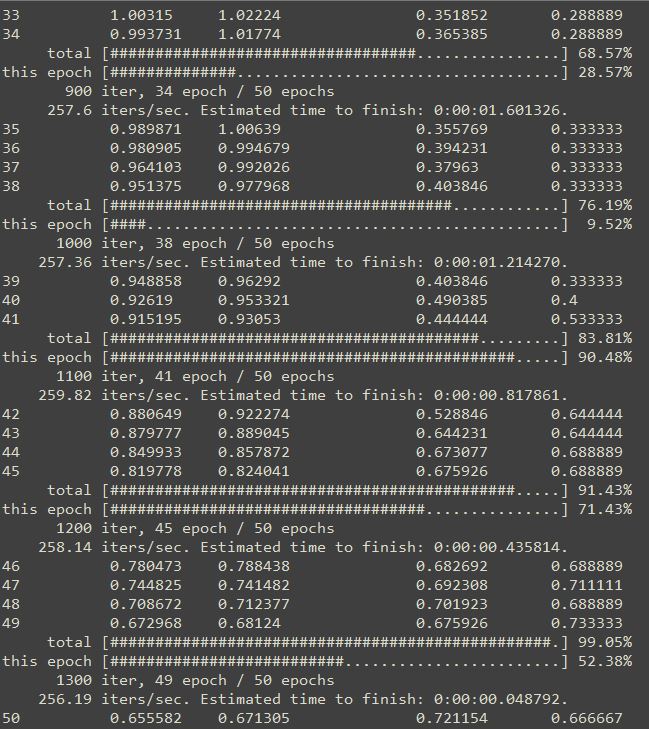
#学習の実行 trainer.run()
”trainer” + “.run()”←これだけで訓練を実行することができます。
実行した結果はこんな感じです。
Step.6 ネットワークの訓練結果
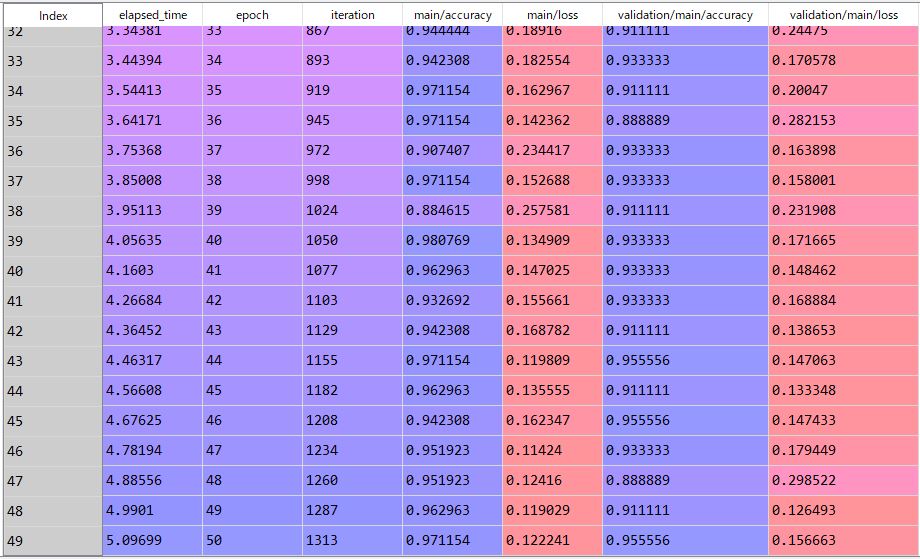
結果グラフ化の準備
#結果のグラフ化
import json
import pandas as pd
f = open("result/iris/log")
json_data = json.load(f)
df_result = pd.DataFrame(json_data)
df_result.tail()
まず先ほど、trainerの部分で ログを保存設定をしました。そのログを見てみましょう。
ログはopen関数で開いた後、それをjson形式でロードします。
そしたら、json形式のログデータをpandasのDataFrame形式で読み込みをします。
そうすると、こんな感じにログが読み込まれます。
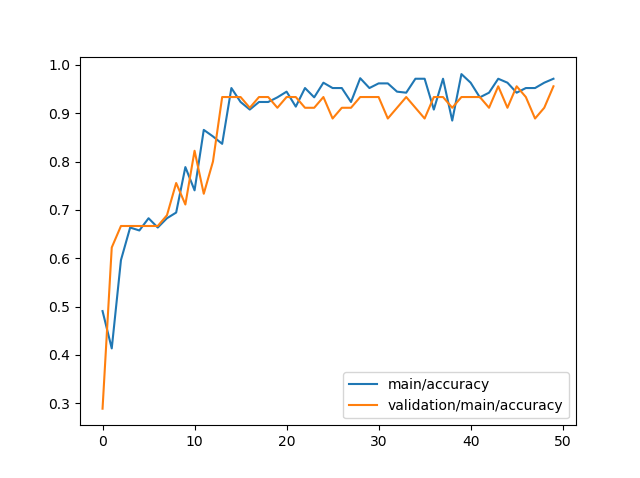
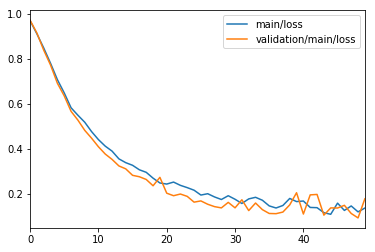
学習精度のグラフ化
df_result[["main/accuracy","validation/main/accuracy"]].plot()
先ほどのログファイルのデータから、学習精度のグラフを出していきましょう。
学習精度のグラフ化する対象は、main/accuracyとvalidation/main/accuracyになります。
4.まとめ
今回はChainerを使って、アヤメの分類問題に挑戦しました。
これまでぶたキムチは深層学習フレームワークであるkerasをずっと使用してきました。
前回紹介したChainerディープラーニング入門でChainerの使い方を学んだので、今回はChainerを実際に使って機械学習に挑戦してみました。
使ってみた感想は、kerasと比較してかなり直感的に使えます。kerasはかなりコード数が少なく深層学習が実装できます。Chainerは違って、ディープラーニングを実装する上でのスッテプをkerasより詳細にコーディングする必要があると感じました。しかしその点、深層学習のモデルや最適化手法のパラメータ更新など、自分で思うようにカスタマイズできる点は非常に使いやすく直感的に使用できると感じました。
これから、Chainerでディープラーニング実装にどんどん挑戦してみたいと思います。


コメント