

今回はタイタニックの生存問題でKaggleの挑戦に挑戦してみましょう。
タイタニックは、映画化にもなったタイタニック号の沈没に関する問題です。
当時の乗客のデータをもとに、どの乗客なら生存し、死亡したのかを予測します。
1.実装環境
python
Editer : spyder
2.タイタニックの生存予測
kaggleの中でも有名なコンペ課題として、タイタニックの生存予測があります。
kaggleの中でもチュートリアル的な問題となります。
この課題に取り組むにあたって、データの準備をする必要があります。
データはKaggleからタイタニックのcsvデータをダウンロードする必要があります。→ https://www.kaggle.com/c/titanic/data
使用するデータは、以下の2つです。
・test.csv
・train.csv
では次に予測に使用できるようにデータを少し加工していきましょう。
3.ソースコード詳細(データのインポート・加工)
import pandas as pd import seaborn as sns import matplotlib.pyplot as plt import os
まずは必要なライブラリをインポートしましょう。
pnadasはpythonにおいてデータ解析を支援する機能を提供するライブラリです。
特に数表及び時系列データを操作するためのデータ構造と演算を提供するライブラリです。
#csvデータのインポート
os.chdir('./Brog_code/taitanic')
train = pd.read_csv('C:/Users/Hayato/Brog_code/taitanic/train.csv')
test =pd.read_csv('C:/Users/Hayato/Brog_code/taitanic/test.csv')
次にタイタニックのデータをインポートしましょう。
タイタニックのデータはkaggleにcsvファイルでアップされているので、そこからダウンロードしてください。
それをpandasを使用して、データフレーム型で読み込ませましょう。
#データの確認(データ) train.head() test.head() #データの確認(データサイズ) print(train.shape) print(test.shape) #データの確認(統計量) train.describe() test.describe()
pandasの機能で、pandas.head()でデータフレームの先頭から任意の数を表示させることができます。
例えば、pandas.head(2)であったら、先頭から2行を表示させます。pandas.head()であったら、5行目まで表示されます。
trainとtestのデータは以下の通りです。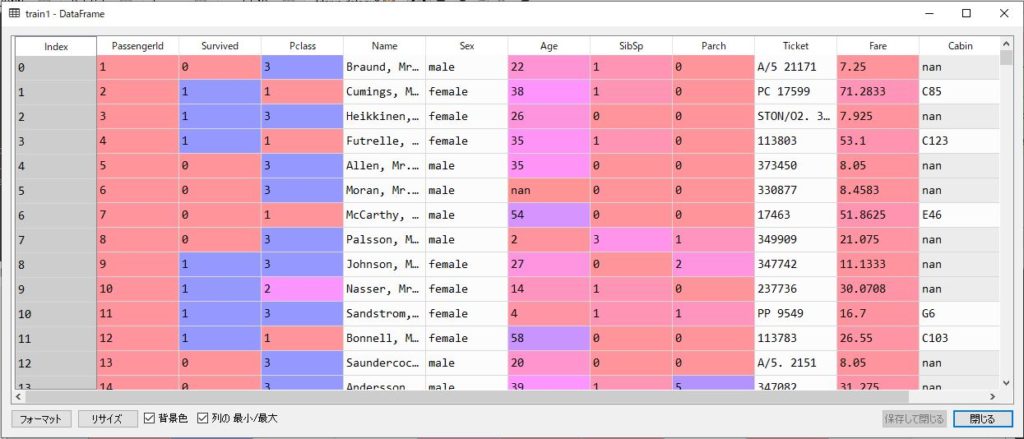
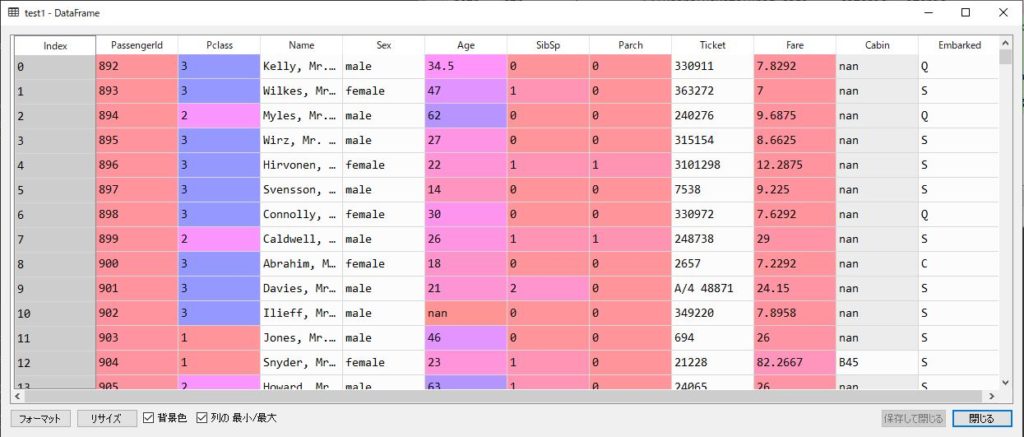
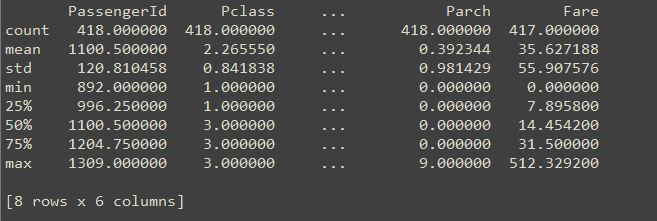
pandasの便利な機能は、pandas.describe()を使用すると、各列ごとに平均や標準偏差、最大値、最小値、最頻値などの統計量を表示させることができます。
#train data
#データセットの前処理:使用しないデータの削除(PassengerId/Name/ticket/cabin)
train = train.drop(["PassengerId","Name","Ticket","Cabin"],axis=1)
#データセットの前処理:欠損値の補完
train["Age"] = train["Age"].fillna(train["Age"].median())
train["Embarked"] = train["Embarked"].fillna("S")
#データセットの前処理:文字列を数値に置換
train["Sex"][train["Sex"] == "male"] = 0
train["Sex"][train["Sex"] == "female"] = 1
train["Embarked"][train["Embarked"] == "S"] = 0
train["Embarked"][train["Embarked"] == "C"] = 1
train["Embarked"][train["Embarked"] == "Q"] = 2
train.head()
今回は、データフレームの項目にあるPassengerId・Name・ticket・cabinのデータは予測に必要ないので削除します。
pandas.drop():行・列を指定して削除することができる。axis=0は行の指定。axis=1は列の指定。

データをよく見ると、”Age”と”Embarked”は欠損値(NaN)があります。
そこで欠損値は平均値で穴埋めしていきます。
pandas.fillna():欠損値を他の値に置換する。値の設定は以下の種類がある。
pandas.fillna(数値)→かっこ内の数値に欠損値が置き換わる
pandas.fillna(.mean())→欠損値をデータフレームの平均値に置き換える
pandas.fillna(.median())→欠損値をデータフレームの中央値に置き換える ←今回はこちらを使用
pandas.fillna(.mode().iloc)→データフレームの平均値に置き換える
さらに、”male”、”female”は1と2に、”Embarked”のS・C・Qは0、1、2に変換して学習できる形にしましょう。
以下が変換した結果です。
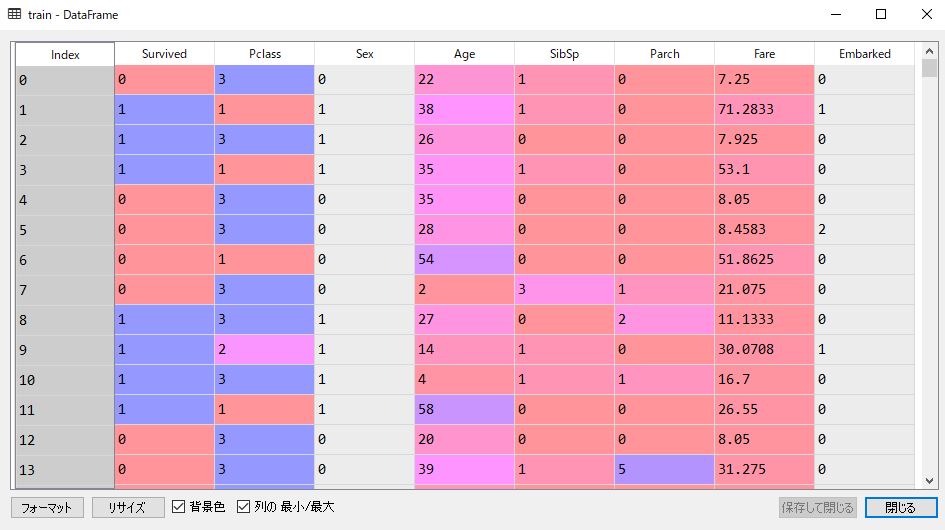
#test data
test = test.drop(["PassengerId","Name","Ticket","Cabin"],axis=1)
test["Age"] = test["Age"].fillna(test["Age"].median())
test["Embarked"] = test["Embarked"].fillna("S")
#データセットの前処理:文字列を数値に置換
test["Sex"][test["Sex"] == "male"] = 0
test["Sex"][test["Sex"] == "female"] = 1
test["Embarked"][test["Embarked"] == "S"] = 0
test["Embarked"][test["Embarked"] == "C"] = 1
test["Embarked"][test["Embarked"] == "Q"] = 2
test.head()
では、同様にtest dataも変換していきましょう。説明は割愛します。
#関連度の高い項目をヒートマップで表示 plt.figure(figsize=(8,6)) sns.heatmap(train.corr(), annot=True, cmap='Blues')
最後に関連度が高いものをヒートマップで表示しましょう。
ヒートマップを作成する目的は、各項目でどの程度相関がみられるのか可視化するためです。
今回のタイタニックのデータを使用したときのヒートマップを以下に示しました。
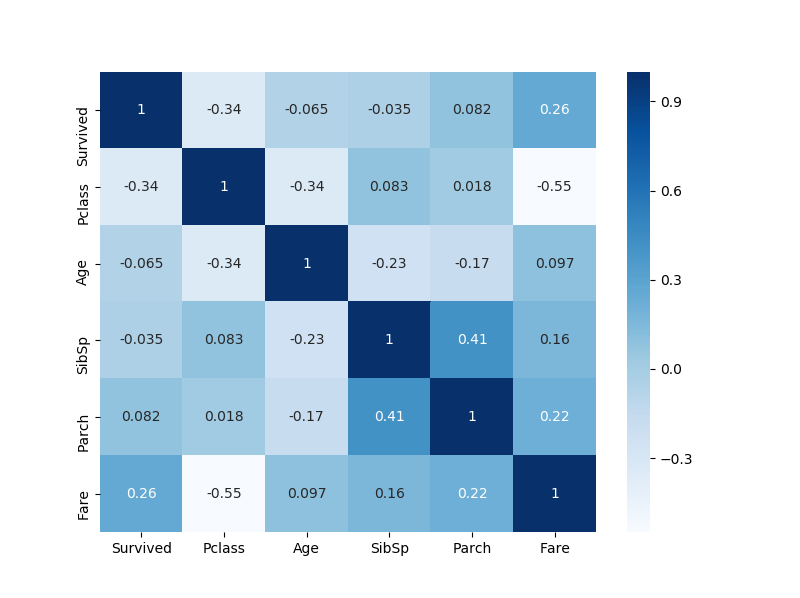
どれも強い相関はみられませんね。
4.ソースコードまとめ(データのインポート・加工)
# -*- coding: utf-8 -*-
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
#csvデータのインポート
train = pd.read_csv("./Brog_code/taitanic/titanic/train.csv")
test =pd.read_csv("./Brog_code/taitanic/titanic/test.csv")
#データの確認(データ)
train.head()
test.head()
#データの確認(データサイズ)
print(train.shape)
print(test.shape)
#データの確認(統計量)
train.describe()
test.describe()
#train data
#データセットの前処理:使用しないデータの削除(PassengerId/Name/ticket/cabin)
train = train.drop(["PassengerId","Name","Ticket","Cabin"],axis=1)
#データセットの前処理:欠損値の補完
train["Age"] = train["Age"].fillna(train["Age"].median())
train["Embarked"] = train["Embarked"].fillna("S")
#データセットの前処理:文字列を数値に置換
train["Sex"][train["Sex"] == "male"] = 0
train["Sex"][train["Sex"] == "female"] = 1
train["Embarked"][train["Embarked"] == "S"] = 0
train["Embarked"][train["Embarked"] == "C"] = 1
train["Embarked"][train["Embarked"] == "Q"] = 2
train.head()
#test data
test = test.drop(["PassengerId","Name","Ticket","Cabin"],axis=1)
test["Age"] = test["Age"].fillna(test["Age"].median())
test["Embarked"] = test["Embarked"].fillna("S")
#データセットの前処理:文字列を数値に置換
test["Sex"][test["Sex"] == "male"] = 0
test["Sex"][test["Sex"] == "female"] = 1
test["Embarked"][test["Embarked"] == "S"] = 0
test["Embarked"][test["Embarked"] == "C"] = 1
test["Embarked"][test["Embarked"] == "Q"] = 2
test.head()
#関連度の高い項目をヒートマップで表示
plt.figure(figsize=(8,6))
sns.heatmap(train.corr(), annot=True, cmap='Blues')
5.おわりに
次回は実際に学習させ、kaggleに提出する方法までやってみましょう。

コメント